很多时候我们都会对M0,M0+,M3,M4,M7,arm7,arm9,CORTEX-A系列,或者说AVR,51,PIC等,一头雾水,只知道是架构,不知道具体是什么,有哪些不同?今天查了些资料,来解解惑,不是很详细,但对此有个大体了解。咱先来当下最火的ARM吧
1.ARM
ARM即以英国ARM(Advanced RISC Machines)公司的内核芯片作为CPU,同时附加其他外围功能的嵌入式开发板,用以评估内核芯片的功能和研发各科技类企业的产品.
ARM 微处理器目前包括下面几个系列,以及其它厂商基于 ARM 体系结构的处理器,除了具有ARM 体系结构的共同特点以外,每一个系列的 ARM 微处理器都有各自的特点和应用领域。
- ARM7 系列
- ARM9 系列
- ARM9E 系列
- ARM10E 系列
- ARM11系列
- Cortex 系列
- SecurCore 系列
- OptimoDE Data Engines
- Intel的Xscale
- Intel的StrongARM ARM11系列
2. Cortex 系列
32位RISCCPU开发领域中不断取得突破,其设计的微处理器结构已经从v3发展到现在的v7。Cortex系列处理器是基于ARMv7架构的,
分为Cortex-M、Cortex-R和Cortex-A三类。由于应用领域的不同,基于v7架构的Cortex处理器系列所采用的技术也不相同。基于v7A的称为“Cortex-A系列。
高性能的Cortex-A15、可伸缩的Cortex-A9、经过市场验证的Cortex-A8处理器以及高效的Cortex-A7和Cortex-A5处理器均共享同一体系结构,因此具有完整的应用兼容性,支持传统的ARM、Thumb指令集
和新增的高性能紧凑型Thumb-2指令集。
1Cortex-M系列
Cortex-M系列又可分为Cortex-M0、Cortex-M0+、Cortex-M3、Cortex-M4;
2Cortex-R系列
Cortex-R系列分为Cortex-R4、Cortex-R5、Cortex-R7;
3Cortex-A 系列
Cortex-A系列分为Cortex-A5、Cortex-A7、Cortex-A8、Cortex-A9、Cortex-A15、Cortex-A50等 ,同样也就有了对应内核的Cortex-M0开发板、Cortex-A5开发板、Cortex-A8开发板、Cortex-A9开发板、
Cortex-R4开发板等等。
4半导体
由于ARM公司只对外提供ARM内核,各大厂商在授权付费使用ARM内核的基础上研发生产各自的芯片,形成了嵌入式ARM CPU的大家庭,提供这些内核芯片的厂商有Atmel、TI、飞思卡尔、NXP、ST、和三星等。
Cortex-M兼容特性
为了能做到Cortex-M软件重用,ARM公司在设计Cortex-M处理器时为其赋予了处理器向下兼容、软件二进制向上兼容特性。
首先看什么是二进制兼容,这个特性主要是针对软件而言,这里指的是当某软件(程序)依赖的头文件或库文件分别升级时,软件功能不受影响。要做到二进制兼容,被软件所依赖的头文件或库文件升级时必须是二进制兼容的。
那么什么又是向上兼容,向上兼容又叫向前兼容,指的是在较低版本处理器上编译的软件可以在较高版本处理器上执行。
跟向上兼容相对的另一个概念叫向下兼容,向下兼容又叫向后兼容,指的是较高版本处理器可以正确运行在较低版本处理器上编译的软件。
所以其实既可以用向上兼容,也可以用向下兼容来形容Cortex-M特性,只不过描述的主语不一样,我们可以说Cortex-M程序是向上兼容的,也可以说Cortex-M处理器是向下兼容的。
具体到Cortex-M处理器时,这个兼容特性表现为:
- 从处理器角度看:CM0指令集和功能模块是最精简的,CM7指令集和功能模块是最丰富的。不存在低版本处理器上存在的特性是高版本处理器所没有的。
- 从软件角度来看:CMSIS提供的头文件和功能函数是二进制向上兼容的,比如某CM0软件App使用的是core_cm0.h头文件,而这个App要在CM7上运行时,不需要使用core_cm7.h再重新编译一次(当然使用新头文件编译后的App也是正常的。)
从MCU内核到MCU实际应用是一个完整的产业链,这个产业链分为五个部分:

其实都是这样,前三个部分有芯片厂家和架构内核公司负责开芯片,后两个部分由研发公司根据芯片设计,开发。
就拿ST为例,ARM公司为最开始的部分,ST(意法半导体)为芯片设计与制造公司,以ARM内核为载体,通过进一步的设计开发,为ARM配备外围的支持,为将计算控制能力应用到电子产品中提供芯片服务
Cortex-M0 处理器简介
ARM公司的Cortex-M0应用于各种微控制器(MCU)中,并可让研发工程师以8位的价位创造32位的的效能,并将传统的8位和16位的处理器升级到更高效、更低功耗的32位处理器。
Cortex-M0是Cortex-M家族中的M0系列。最大特点是低功耗的设计。Cortex-M0为32位、3级流水线RISC处理器,其核心仍为冯.诺依曼结构,是指令和数据共享同一总线的架构。作为新一代的处理器,Cortex-M0的设计进行了许多的改革与创新,如系统存储器地址映像(system address map)、改善效率并增强确定性的嵌套向量中断系统(NVIC)与不可屏蔽中断(NMI)、全新的硬件除错单元等等,都带给了使用者全新的体验和更便利、 更有效率的操作。
技术架构
CortexM0其核心架构为ARMv6M,其运算能力可以达到0.9 DMIPS/MHz,而与其他的16位与8位处理器相比,由于CortexM0的运算性能大幅提高,所以在同样任务的执行上CortexM0只需较低的运行速度,而大幅降低了整体的动态功耗。
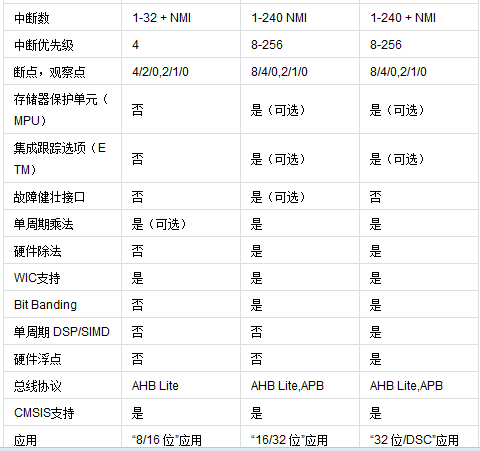
Cortex—M0属于ARMv6-M架构,包括1颗专为嵌入式应用而设计的ARM核、紧耦合的可嵌套中断微控制器NVIC、可选的唤醒中断控制器WIC,对外提供了基于AMBA结构(高级微控制器总线架构)的AHB-lite总线和基于CoreSight技术的SWD或JTAG调试接口,如图所示。Cortex-M0微控制器的硬件实现包含多个可配置选项:中断数量、WIC、睡眠模式和节能措施、存储系统大小端模式、系统滴答时钟等,半导体厂商可以根据应用需要选择合理的配置。

系统总线基于AHB_Lite高级高性能总线协议。外设总线基于APB高级外设总线协议,通过一个转换桥连接到AHB上,这只是Cortex-M0内核的大概模式.
特点
1)能耗效率
CortexM0的运行效率很高(0.9DMIPS/MHz),能在较少的周期里完成一项任务。这意味着CortexM0可以在大部分的时间里处于休眠状态,消耗很少的能量,具有良好的能耗效率。同样较小的逻辑门数也降低了待机电流。而高效的中断控制器(NVIC)需要很小的中断开销。
2)代码密度
Cortex-M0基于Thumb-2的指令集,比用8位或者16位架构实现的代码还要少,因此用户可以选择具有较小Flash空间的芯片。可以降低系统功耗。[1]
3) 易于使用
Cortex-M0适用于C语言编程,并且被许多编译器支持。可以用C语言直接编程中断例程,而无需使用汇编语言。同时Cortex-M0还被多种开发工具支持。包括很多开源的嵌入式操作系统同样支持Cortex-M0。
Cortex-M0 处理器简介
1. Cortex-M0 处理器基于冯诺依曼架构(单总线接口),使用32位精简指令集(RISC),该指令集被称为Thumb指令集。与之前相比,新的指令集增加了几条ARMv6架构的指令,并且加入了eThumb-2指令集的部分指令。Thumb-2技术扩展了Thumb的应用,允许所有的操作都可以在同一种CPU状态下执行。Thumb指令集既包括16位指令,也包括32位指令。C编译器生成的指令大部分是16位的,当16位的指令无法实现所需要的操作时,32位指令就会发挥作用。这样以来,在代码密度得到提升的同时,还避免了两套指令集之间进行切换带来的开销
2. Cortex-M0总共支持56个基本指令,其中某些指令可能会有多种形式。相对于Cortex-M0较小的指令集,其处理器的能力可不一般,因为Thumb是经过高度优化的指令集。从理论来说,由于读写存储是的指令是相互独立的,而且算数或逻辑操作的指令使用寄存器,Cortex-M0处理器可以被归到加载-存储(load-store)结构中。
3. 处理器核心包括:
- 寄存器组 包含16个32位寄存器,其中有一些特殊寄存器
- 算术逻辑单元
- 数据总线
- 控制逻辑
流水线根据设计可分为三种状态: 取指、译码、执行。
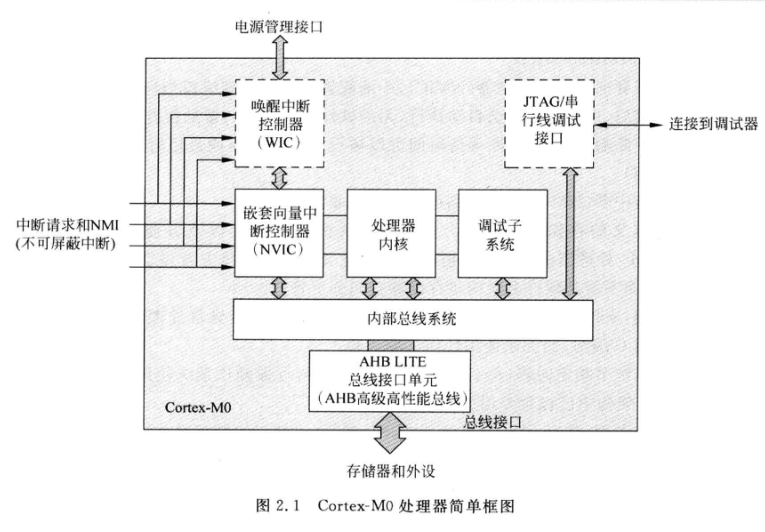
4. 嵌套向量中断控制器(NVIC)可以处理最多32个中断请求和一个不可屏蔽中断(NMI)输入。
5. NVIC需要比较这个在执行中断和请求中断的优先级,,然后自动执行高优先级的中断。
6. 如果要处理一个中断,NVIC会和处理器进行通信,通知处理器执行中断处理程序。
7. 唤醒中断控制器(WIC)为可选的单元,在低功耗应用中,在关闭了处理器大部分模块后,微控制器会进入待机装填,此时,WIC可以在NVIC和处理器处于休眠的情况下,执行中断屏蔽功能。当WIC检测到一个中断时,会通知电源管理部分给系统商店,让NVIC和处理器内核执行剩余的中断处理。
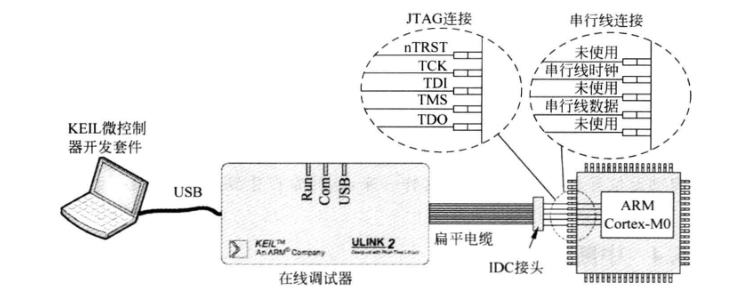
8. 关于调试子系统,当调试事件发生时,处理器内核会被置于暂停状态,这是开发人员可以检查当前处理器的状态。硬件调试工具有JTAG和SWD(串行线调试)。 ![image]()
ARM Cortex-M0 处理器的特性
系统特性
- thumb指令集,具有高效和高代码密度
- 高性能,最高达到0.9DMIPS/MHz
- 内置的嵌套向量中断控制器(NVIC),中断配置和异常处理容易
- 确定的中断响应事件,中断等待事件可以被设定为固定值或最短事件(最小16个时钟周期)
- 不可屏蔽中断(NMI),对高可靠性系统非常重要
- 内置的系统节拍定时器(systick)。24位定时器,可被操作系统使用,或者用作通用定时器,架构中已经包含专用的异常类型
- 请求管理调用,具有SVC异常和PendSV异常(可挂起的管理服务),支持嵌入式os的多种操作
- 架构定义的休眠模式和进入休眠的指令,休眠特性能大大降低能量的消耗。由于进入休眠状态需要使用特定的指令,而不是使用寄存器,架构定义的休眠模式也提高了软件的可移植性。
- 异常处理可以捕获到系统中的多种错误。
应用特性
- 中断数量可配置
- 支持大端或小端存储器
- 可选择的唤醒中断控制器(WIC),处理器可以在休眠状态下掉电以降低功耗,而WIC可以在中断发生时唤醒系统
Cortex-M3
Cortex-M3是一个32位的核,在传统的单片机领域中,有一些不同于通用32位CPU应用的要求。在工控领域,用户要求具有更快的中断速度,Cortex-M3采用了Tail-Chaining
中断技术,完全基于硬件进行
中断处理,最多可减少12个
时钟周期数,在实际应用中可减少70%中断。
概述
Cortex-M3是一个32位处理器内核。内部的数据路径是32位的,寄存器是32位的,存储器接口也是32位的。CM3采用了哈佛结构,拥有独立的指令总线和数据总线,可以让取指与数据访问并行不悖。这样一来数据访问不再占用指令总线,从而提升了性能。为实现这个特性,CM3内部含有好几条总线接口,每条都为自己的应用场合优化过,并且它们可以并行工作。但是另一方面,指令总线和数据总线共享同一个存储器空间(一个统一的存储器系统)。换句话说,不是因为有两条总线,可寻址空间就变成8GB了。
比较复杂的应用可能需要更多的存储系统功能,为此CM3提供一个可选的MPU,而且在需要的情况下也可以使用外部的cache。另外在CM3中,Both小端模式和大端模式都是支持的。
CM3内部还附赠了好多调试组件,用于在硬件水平上支持调试操作,如指令断点,数据观察点等。另外,为支持更高级的调试,还有其它可选组件,包括指令跟踪和多种类型的调试接口。
内核架构
ARMCortex-M3采用哈佛结构,并选择了适合于微控制器应用的三级流水线,但增加了分支预测功能。
现代处理器大多采用指令预取和流水线技术,以提高处理器的指令执行速度。流水线处理器在正常执行指令时,如果碰到分支(跳转)指令,由于指令执行的顺序可能会发生变化,指令预取队列和流水线中的部分指令就可能作废,而需要从新的地址重新取指、执行,这样就会使流水线“断流”,处理器性能因此而受到影响。特别是现代C语言程序,经编译器优化生成的目标代码中,分支指令所占的比例可达10-20%,对流水线处理器的影响会的更大。为此,现代高性能流水线处理器中一般都加入了分支预测部件,就是在处理器从存储器预取指令时,当遇到分支(跳转)指令时,能自动预测跳转是否会发生,再从预测的方向进行取指,从而提供给流水线连续的指令流,流水线就可以不断地执行有效指令,保证了其性能的发挥。
ARMCortex-M3内核的预取部件具有分支预测功能,可以预取分支目标地址的指令,使分支延迟减少到一个时钟周期。
针对业界对ARM处理器中断响应的问题,Cortex-M3首次在内核上集成了嵌套向量中断控制器(NVIC)。Cortex-M3的中断延迟只有12个时钟周期(ARM7需要24-42个周期);Cortex-M3还使用尾链技术,使得背靠背(back-to-back)中断的响应只需要6个时钟周期(ARM7需要大于30个周期)。Cortex-M3采用了基于栈的异常模式,使得芯片初始化的封装更为简单。
Cortex-M3加入了类似于8位处理器的内核低功耗模式,支持3种功耗管理模式:通过一条指令立即睡眠;异常/中断退出时睡眠;深度睡眠。使整个芯片的功耗控制更为有效。
特点
高性能
? 许多指令都是单周期的——包括乘法相关指令。并且从整体性能上,Cortex-M3比得过绝大多数其它的架构。
? 指令总线和数据总线被分开,取值和访内可以并行不悖
? Thumb-2的到来告别了状态切换的旧世代,再也不需要花时间来切换于32位ARM状态和16位Thumb状态之间了。这简化了软件开发和代码维护,使产品面市更快。
? Thumb-2指令集为编程带来了更多的灵活性。许多数据操作现在能用更短的代码搞定,这意味着Cortex-M3的代码密度更高,也就对存储器的需求更少。
? 取指都按32位处理。同一周期最多可以取出两条指令,留下了更多的带宽给数据传输。
? Cortex-M3的设计允许单片机高频运行(现代半导体制造技术能保证100MHz以上的速度)。即使在相同的速度下运行,CM3的每指令周期数(CPI)也更低,于是同样的MHz下可以做更多的工作;另一方面,也使同一个应用在CM3上需要更低的主频。
先进的中断处理功能
? 内建的嵌套向量中断控制器支持多达240条外部中断输入。向量化的中断功能剧烈地缩短了中断延迟,因为不再需要软件去判断中断源。中断的嵌套也是在硬件水平上实现的,不需要软件代码来实现。
? Cortex-M3在进入异常服务例程时,自动压栈了R0-R3, R12, LR, PSR和PC,并且在返回时自动弹出它们,这多清爽!既加速了中断的响应,也再不需要汇编语言代码了。
? NVIC支持对每一路中断设置不同的优先级,使得中断管理极富弹性。最粗线条的实现也至少要支持8级优先级,而且还能动态地被修改。
? 优化中断响应还有两招,它们分别是“咬尾中断机制”和“晚到中断机制”。
? 有些需要较多周期才能执行完的指令,是可以被中断-继续的——就好比它们是一串指令一样。这些指令包括加载多个寄存器(LDM),存储多个寄存器(STM),多个寄存器参与的PUSH,以及多个寄存器参与的POP。
? 除非系统被彻底地锁定,NMI(不可屏蔽中断)会在收到请求的第一时间予以响应。对于很多安全-关键(safety-critical)的应用,NMI都是必不不可少的(如化学反应即将失控时的紧急停机)。
低功耗
? Cortex-M3需要的逻辑门数少,所以先天就适合低功耗要求的应用(功率低于0.19mW/MHz)在内核水平上支持节能模式(SLEEPING和SLEEPDEEP位)。通过使用“等待中断指令(WFI)”和“等待事件指令(WFE)”,内核可以进入睡眠模式,并且以不同的方式唤醒。另外,模块的时钟是尽可能地分开供应的,所以在睡眠时可以把CM3的大多数“官能团”给停掉。
? CM3的设计是全静态的、同步的、可综合的。任何低功耗的或是标准的半导体工艺均可放心饮用。
系统特性
? 系统支持“位寻址带”操作(8051位寻址机制的“威力大幅加强版”),字节不变的大端模式,并且支持非对齐的数据访问。
? 拥有先进的fault处理机制,支持多种类型的异常和faults,使故障诊断更容易。
? 通过引入banked堆栈指针机制,把系统程序使用的堆栈和用户程序使用的堆栈划清界线。如果再配上可选的MPU,处理器就能彻底满足对软件健壮性和可靠性有严格要求的应用。
调试支持
? 在支持传统的JTAG基础上,还支持更新更好的串行线调试接口。
? 基于CoreSight调试解决方案,使得处理器哪怕是在运行时,也能访问处理器状态和存储器内容。
? 内建了对多达6个断点和4个数据观察点的支持。
? 可以选配一个ETM,用于指令跟踪。数据的跟踪可以使用DWT
? 在调试方面还加入了以下的新特性,包括fault状态寄存器,新的fault异常,以及闪存修补 (patch)操作,使得调试大幅简化。
? 可选ITM模块,测试代码可以通过它输出调试信息,而且“拎包即可入住”般地方便使用。
编程模式
Cortex-M3处理器采用ARMv7-M架构,它包括所有的16位Thumb
指令集和基本的32位Thumb-2
指令集架构,Cortex-M3处理器不能执行ARM指令集。
Thumb-2在Thumb
指令集架构(ISA)上进行了大量的改进,它与Thumb相比,具有更高的代码密度并提供16/32位指令的更高性能。
关于工作模式
Cortex-M3处理器支持2种工作模式:线程模式和处理模式。在复位时处理器进入“线程模式”,异常返回时也会进入该模式,特权和用户(非特权)模式代码能够在“线程模式”下运行。
出现异常模式时处理器进入“处理模式”,在处理模式下,所有代码都是特权访问的。
关于工作状态
Cortex-M3处理器有2种工作状态。
Thumb状态:这是16位和32位“
半字对齐”的Thumb和Thumb-2指令的执行状态。
调试状态:处理器停止并进行调试,进入该状态。
Cortex-M4
基本简介
ARMCortex™-M4处理器是由ARM专门开发的最新嵌入式处理器,在M3的基础上强化了运算能力,新加了浮点、DSP、并行计算等,用以满足需要有效且易于使用的控制和信号处理功能混合的数字信号控制市场。其高效的信号处理功能与Cortex-M处理器系列的低功耗、低成本和易于使用的优点的组合,旨在满足专门面向电动机控制、汽车、电源管理、嵌入式音频和工业自动化市场的新兴类别的灵活解决方案。
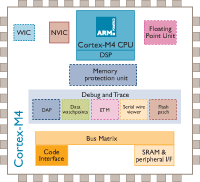
特性
ARMCortex™-M4处理器内核是在Cortex-M3内核基础上发展起来的,其性能比Cortex-M3提高了20%。新增加了浮点、DSP、并行计算等。用以满足需要有效且易于使用的控制和信号处理功能混合的数字信号控制市场。其高效的信号处理功能与Cortex-M处理器系列的低功耗、低成本和易于使用的优点相结合。
Cortex-M4提供了无可比拟的功能,将32位控制与领先的数字信号处理技术集成来满足需要很高能效级别的市场。
Cortex-M4处理器采用一个扩展的单时钟周期乘法累加(MAC)单元、优化的单指令多数据(SIMD)指令、饱和运算指令和一个可选的单精度浮点单元(FPU)。这些功能以表现
ARMCortex-M系列处理器特征的创新技术为基础。包括
·RISC处理器内核,高性能32位CPU、具有确定性的运算、低延迟3阶段管道,可达1.25DMIPS/MHz;
·Thumb-2指令集,16/32位指令的最佳混合、小于8位设备3倍的代码大小、对性能没有负面影响,提供最佳的代码密度;
·低功耗模式,集成的睡眠状态支持、多电源域、基于架构的软件控制;
·嵌套矢量中断控制器(NVIC),低延迟、低抖动中断响应、不需要汇编编程、以纯C语言编写的中断服务例程,能完成出色的中断处理;
·工具和RTOS支持,广泛的第三方工具支持、Cortex微控制器软件接口标准(CMSIS)、最大限度地增加软件成果重用;
·CoreSight调试和跟踪,JTAG或2针串行线调试(SWD)连接、支持多处理器、支持实时跟踪。
此外,该处理器还提供了一个可选的内存保护单元(MPU),提供低成本的调试/追踪功能和集成的休眠状态,以增加灵活性。嵌入式开发者将得以快速设计并推出令人瞩目的终端产品,具备最多的功能以及最低的功耗和尺寸。
处理技术
Cortex-M4 处理器已设计为具有适用于数字信号控制市场的多种高效
信号处理功能。Cortex-M4 处理器采用扩展的单周期乘法累加 (MAC) 指令、优化的 SIMD 运算、饱和运算指令和一个可选的单精度浮点单元 (FPU)。这些功能以表现 ARM Cortex-M 系列处理器特征的创新技术为基础。

主要功能
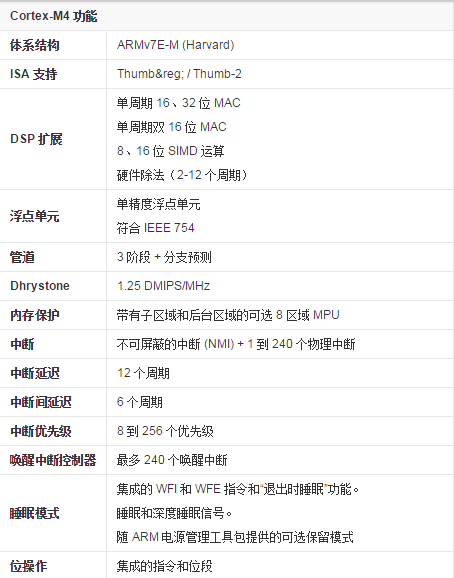
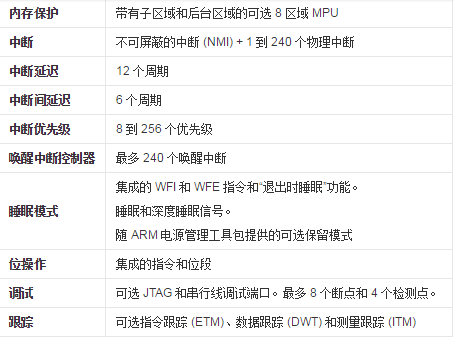
从图上可以看出三者功能上的异同点。它们的不同点也决定了三者的不同应用场合。M4相比较前两者主要的变化在于数字运算能力上的增强,增加了DSP运算指令、SIMD(Single Instruction Multiple Data,单指令多数据流)指令集、FPU(浮点运算单元,可选)。
从图中足以看出M4内核的强大,同时Cortex-M 系列处理器都是二进制向上兼容的,这使得软件重用以及从一个 Cortex-M 处理器无缝发展到另一个成为可能(图3):
下面就增强的三个功能进行说明:
1、DSP指令集
所谓集成DSP功能并不是说M4内核是一个M3+DSP的双核处理器(目前个人知道的这类处理器是TI的达芬奇系列,主要应用于语音、视频图像有关的数字多媒体领域)。而是只是增加了DSP功能的指令集(单周期的运算指令),能在一个周期内完成指令操作。在官方的CMSIS标准工程库中已经集成,可以直接使用(有关内容在以后文章中介绍)。
图表展示了处理器运行在相同的速度下Cortex - M3和Cortex - M4在数字信号处理能力方面的相对性能比较。
在下面的数字,Y轴代表执行给出的计算用的相对的周期数。 因此,循环数越小,性能越好。以Cortex - M3作为参考,Cortex - M4的性能计算,性能比大概为其周期计数的倒数。举例说明,PID功能,Cortex - M4的周期数是与Cortex - M3的约0.7倍,因此相对性能是1/0.7,即1.4倍。
Cortex - M系列16位循环计数功能
Cortex - M系列32位循环计数功能
这很清楚的表明,Cortex - M4在数字信号处理方面对比Cortex - M3的16位或32位操作有着很大的优势。
Cortex-M4执行的所有的DSP指令集都可以在一个周期完成,Cortex - M3需要多个指令和多个周期才能完成的等效功能。即使是PID算法——通用DSP运算中最耗费资源的工作,Cortex - M4也能提供了一个1.4倍的性能得改善 。另一个例子,MP3解码在Cortex-M3需要20-25Mhz,而在Cortex-M4只需要10-12MHz。
2. 32位乘法累加(MAC)
32位乘法累加(MAC)包括新的指令集和针对Cortex - M4硬件执行单元的优化它是能够在单周期内完成一个 32 × 32 + 64 - > 64 的操作 或 两个16 × 16 的操作。如下表列出了这个单元的计算能力。
3 .SIMD
(Single Instruction Multiple Data,单指令多数据流)能够复制多个操作数,并把它们打包在大型寄存器的一组指令集,例:3DNow!、SSE。以同步方式,在同一时间内执行同一条指令。
SIMD在性能上的优势:
以加法指令为例,单指令单数据(SISD)的CPU对加法指令译码后,执行部件先访问内存,取得第一个操作数;之后再一次访问内存,取得第二个操作数;随后才能进行求和运算。而在SIMD型的CPU中,指令译码后几个执行部件同时访问内存,一次性获得所有操作数进行运算。这个特点使SIMD特别适合于多媒体应用等数据密集型运算。
如:AMD公司引以为豪的3D NOW! 技术实质就是SIMD,这使K6-2、雷鸟、毒龙处理器在音频解码、视频回放、3D游戏等应用中显示出优异的性能。
4.FPU
FPU是Cortex - M4浮点运算的可选单元。因此它是一个专用于浮点任务的单元。这个单元通过硬件提升性能,能处理单精度浮点运算,并与IEEE 754标准 兼容。这完成了ARMv7 - M架构单精度变量的浮点扩展。FPU扩展了寄存器的程序模型与包含32个单精度寄存器的寄存器文件。这些可以被看作是:
·16个64位双字寄存器,D0 - D15
·32个32位单字寄存器,S0 - S31 该FPU提供了三种模式运作,以适应各种应用
·全兼容模式(在全兼容模式,FPU处理所有的操作都遵循IEEE754的硬件标准)
·Flush-to-zero
冲洗到零模式(设置FZ位浮点状态和控制寄存器FPSCR [24]到flush-to-zero 模式。在此模式下,FPU 在运算中将所有不正常的输入操作数的算术CDP操作当做0.除了当从零操作数的结果是合适的情况。VABS,VNEG,VMOV 不会被当做算术CDP的运算,而且不受flush-to-zero 模式影响。结果是微小的,就像在IEEE 754 标准的描述的那样,在目标精度增加的幅度小于四舍五入后最低正常值,被零取代。IDC的标志位,FPSCR [7],表示当输入Flush时变化。UFC标志位,FPSCR [3],表示当Flush结束时变化)
·默认的NaN模式(DN位的设置,FPSCR [25],会进入NaN的默认模式。在这种模式下,如对任何算术数据处理操作的结果,涉及一个输入NaN,或产生一个NaN结果,会返回默认的NaN。仅当VABS,VNEG,VMOV运算时,分数位增加保持。所有其他的CDP运算会忽略所有输入NaN的小数位的信息)。具体指令请自行查看手册。
Cortex-M功能模块差异
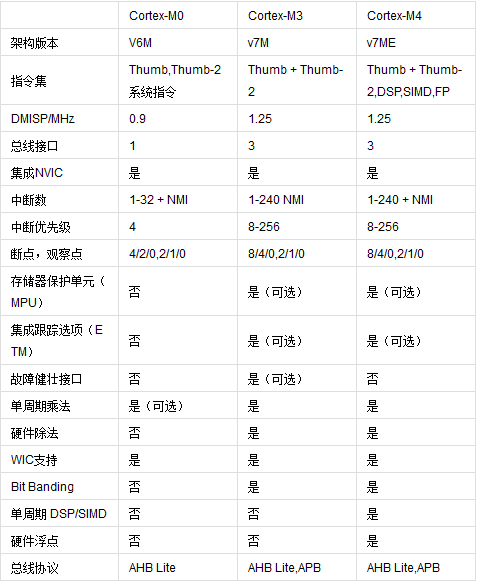
由于CM1主要是用在FPGA产品中,故下面对比忽略CM1。我们知道CM处理器是向下兼容的,故CM功能模块是随着版本的升级而逐步增加的,我们逐步从最低版本开始对比。
2.1 CM0 vs CM0+
先来聊聊CM0与CM0+,从最基准的CM0模块看起:

- ARMv6-M CPU内核:ARM公司于2007年推出的内核。冯·诺依曼体系结构,3级流水线,支持大部分Thumb和小部分Thumb-2指令集,所有指令一共57条。此外还内嵌32-bit返回结果的硬件乘法器。
- NVIC嵌套向量中断控制器:用于CPU在正常Run模式下中断管理。最大支持32个外部中断,外部中断可设4级抢占优先级(2bit)。
- WIC唤醒中断控制器:用于CPU在低功耗Sleep模式下中断管理。
- AHB-Lite总线:一条32bit
AMBA-3标准的高性能system总线负责所有Flash、SRAM中指令和数据存取。
- 调试模块:0-4个硬件断点Breakpoint,0-2个数据监测点Watchpoint。
- DAP调试接口:通过DAP模块支持JTAG和SWD接口。

那么CM0+到底改进了什么?
- ARMv6-M CPU内核:流水线改为2级(很多8bit MCU都是2级流水线,主要用于降低功耗)
- NVIC嵌套向量中断控制器:增加了VTOR即中断重定向功能。
那么CM0+到底增加了什么?
- MPU存储器保护单元:提供硬件方式管理和保护内存,控制访问权限,最大可将内存分为8*8个region。内存越权访问,将返回MemManage
Fault。
- MTB片上跟踪单元:用户体验更好的的跟踪调试,优化的异常捕获机制,可以更快地定位bug。
- Fast I/O:可单周期访问的快速I/O口,更易于Bit-banging(比如GPIO模拟SPI、IIC协议)。
2.2 CM0+ vs CM3

前面比较完了CM0与CM0+,再来看看CM3比CM0+增强在了哪里:
那么CM3到底改进了什么?
- ARMv7-M CPU内核:ARM公司于2004年推出的内核。哈佛体系结构,3级流水线+分支预测,支持全部的Thumb和Thumb-2指令集。内嵌32-bit硬件乘法器可返回64-bit运算结果,且新增32-bit硬件除法器。
- NVIC嵌套向量中断控制器:最大支持240个外部中断,中断优先级可分组(抢占优先级、响应优先级),8bit优先级设置(最大128级抢占优先级(对应最小2级响应优先级),最大256级响应优先级(对应无抢占优先级))。
- 3x AHB-Lite总线:除了原system总线负责SRAM存取外,还新增两条ICode、DCode总线分别完成Flash上指令和数据存取。
- 调试模块:0-8个硬件断点Breakpoint,0-4个数据监测点Watchpoint。
- ITM/ETM跟踪单元:ITM更好地支持printf风格debug,ETM提供实时指令和数据跟踪。
那么CM3到底增加了什么?
额,CM3相比CM0+并没有增加什么独有模块,反倒是少了Fast I/O Port,实际上Fast I/O Port是CM家族里CM0+所独有的模块。
2.3 CM3 vs CM4

前面比较完了CM0+与CM3,再来看看CM4比CM3增强在了哪里:
那么CM4到底改进了什么?
- ARMv7E-M CPU内核:增加了DSP相关指令支持。
那么CM4到底增加了什么?
- DSP数字信号处理单元:新增支持单周期16/32-bit MAC、dual 16-bit
MAC, 8/16-bit SIMD算法的数字信号处理单元。
- FPU浮点运算单元:新增单精度(float型)兼容IEEE-754标准的浮点运算单元(VFPv4-SP)。
2.4 CM4 vs CM7
前面比较完了CM3与CM4,再来看看CM7比CM4增强在了哪里:
那么CM7到底改进了什么?
- ARMv7E-M CPU内核:6级流水线+分支预测。
- 2x AHB-Lite总线:精简为2条AHB总线,其中AHB-P外设接口完成原来system总线功能, AHB-S从属接口负责外部总线控制器(如DMA)功能以及与TCM接口功能。
- MPU存储器保护单元:最大可将内存分为16*8个region。
- FPU浮点运算单元:新增双精度(double型)兼容IEEE-754标准的浮点运算单元(VFPv5)。

那么CM7到底增加了什么?
- I/D-Cache缓存区:即是我们通常理解的L1
Cache,每个Cache大小为4-64KB。
- I/D-TCM紧密耦合存储器:紧密的与处理器内核相耦合的RAM,提供与Cache相当的性能,但比Cache更具确定性,memory最大均为16MB。
- ECC特性:对L1
Cache提供错误校正和恢复功能,提高系统的可靠性。
- AXI-M总线:基于AMBA
4的64bit AXI总线,用于支持挂在系统上的L2
memory。
- 最近在关注Cortex-M处理器,针对目前进入大众视野的M0、M3、M4做了如下简单对比,内容来自ARM等官网,这里仅仅是整理了下,看起来更直观点,呵呵。
-
- Cortex-M 系列针对成本和功耗敏感的 MCU 和终端应用(如智能测量、人机接口设备、汽车和工业控制系统、大型家用电器、消费性产品和医疗器械)的混合信号设备进行过优化。.
- 一、比较Cortex-M 处理器
- Cortex-M 系列处理器都是二进制向上兼容的,这使得软件重用以及从一个 Cortex-M 处理器无缝发展到另一个成为可能。
- M Cortex-M 技术
- CMSIS
- ARM Cortex 微控制器软件接口标准 (CMSIS)是 Cortex-M 处理器系列的与供应商无关的硬件抽象层。 使用 CMSIS,可以为接口外设、实时操作系统和中间件实现一致且简单的软件接口,从而简化软件的重用、缩短新微控制器开发人员的学习过程,并缩短新产品的上市时间。
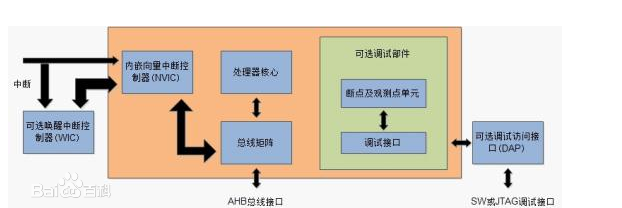
- 深入:嵌套矢量中断控制器 (NVIC)
- NVIC 是 Cortex-M 处理器不可或缺的部分,它为处理器提供了卓越的中断处理能力。
- Cortex-M 处理器使用一个矢量表,其中包含要为特定中断处理程序执行的函数的地址。接受中断时,处理器会从该矢量表中提取地址。
- 为了减少门数并增强系统灵活性,Cortex-M 处理器使用一个基于堆栈的异常模型。出现异常时,系统会将关键通用寄存器推送到堆栈上。完成入栈和指令提取后,将执行中断服务例程或故障处理程序,然后自动还原寄存器以使中断的程序恢复正常执行。使用此方法,便无需编写汇编器包装器了(而这是对基于 C 语言的传统中断服务例程执行堆栈操作所必需的),从而使得应用程序的开发变得非常容易。NVIC支持中断嵌套(入栈),从而允许通过运用较高的优先级来较早地为某个中断提供服务。
- 在硬件中完成对中断的响应
- Cortex-M 系列处理器的中断响应是从发出中断信号到执行中断服务例程的周期数。它包括:
- 检测中断
- 背对背或迟到中断的最佳处理(参见下文)
- 提取矢量地址
- 将易损坏的寄存器入栈
- 跳转到中断处理程序
- 这些任务在硬件中执行,并且包含在为 Cortex-M 处理器报出的中断响应周期时间中。在其他许多体系结构中,这些任务必须在软件的中断处理程序中执行,从而引起延迟并使得过程十分复杂。
-
- NVIC 中的尾链
- 在背对背中断的情况下,传统系统会重复完整的状态保存和还原周期两次,从而导致更高的延迟。Cortex-M处理器通过在 NVIC
硬件中实现尾链技术简化了活动中断和挂起的中断之间的转换。处理器状态会在比软件实现时间更少的周期内自动保存在中断条目上并在中断退出时还原,从而显著提升低 MHz 系统的性能。
-
- NVIC 对迟到的较高优先级中断的响应
- 如果在为上一个中断执行堆栈推送期间较高优先级的中断迟到,NVIC 会立即提取新的矢量地址来为挂起的中断提供服务,如上所示。Cortex-M
NVIC 对这些可能性提供具有确定性的响应并支持迟到和抢占。
-
- NVIC 进行的堆栈弹出抢占
- 同样,如果异常到达,NVIC 将放弃堆栈弹出并立即为新的中断提供服务,如上所示。通过抢占并切换到第二个中断而不完成状态还原和保存,NVIC 以具有确定性的方式实现了缩短延迟。
再来说说ARM7,ARM9系列,
ARM9
ARM9系列处理器是英国ARM公司设计的主流嵌入式处理器,主要包括ARM9TDMI和ARM9E-S等系列。
基本概述
ARM9采用哈佛体系结构,指令和数据分属不同的总线,可以并行处理。在流水线上,ARM7是三级流水线,ARM9是五级流水线。由于结构不同,ARM7的执行效率低于ARM9。平时所说的ARM7、ARM9实际上指的是ARM7TDMI、ARM9TDMI软核,这种处理器软核并不带有MMU和cache,不能够运行诸如linux这样的嵌入式操作系统。而ARM公司对这种架构进行了扩展,所以有了ARM710T、ARM720T、ARM920T、ARM922T等带有MMU和cache的处理器内核。
主要特性编辑
融合了ARM920T™ ARM® Thumb® 处理器
– 工作于180 MHz时性能高达200 MIPS,存储器管理单元
– 16-K 字节的数据缓存,16-K字节的指令缓存,写缓冲器
– 含有调试信道的内部仿真器
– 中等规模的嵌入式宏单元结构( 仅针对256 BGA 封装)
· 低功耗:VDDCORE电流为30.4 mA 待机模式电流为3.1 mA
· 附加的嵌入式存储器
– SRAM为16K ;ROM为128K
· 外部总线接口(EBI)
– 支持SDRAM,静态存储器, Burst Flash,无缝连接的CompactFlash®,
SmartMedia™及NAND Flash
· 提高性能而使用的系统外设:
– 增强的时钟发生器与电源管理控制器
– 两个有双PLL的片上振荡器
– 低速的时钟操作模式与软件功耗优化能力
– 四个可编程的外部时钟信号
– 包括周期性中断、看门狗及第二计数器的系统定时器
– 有报警中断的实时时钟
– 调试单元、两线UART并支持调试信道
– 有8 个优先级的高级中断控制器,独立的可屏蔽中断源,伪中断保护
– 7个外部中断源及1 个快速中断源
– 有122个可编程I/O口线的四个32 位PIO控制器,各线均有输入变化中断及开漏能力
– 20通道的外设数据控制器(DMA)
· 10/100 Base-T 型以太网卡接口
– 独立的媒体接口(MII)或简化的独立媒体接口(RMII)
– 对于接收与发送有集成的28 字节FIFO及专用的DMA 通道
· USB 2.0 全速(12 M比特/秒) 主机双端口
– 双片上收发器(208引脚PQFP封装中仅为一个)
– 集成的FIFO及专用的DMA 通道
· USB 2.0 全速(12 M比特/秒) 器件端口
– 片上收发器, 2-K字节可配置的集成FIFO
· 多媒体卡接口(MCI)
– 自动协议控制及快速自动数据传输
– 与MMC及SD存储器卡兼容,支持两个SD存储器
· 3个同步串行控制器(SSC)
– 每个接收器与发送器有独立的时钟及帧同步信号
– 支持I2S模拟接口,时分复用
– 32比特的高速数据流传输能力
· 4个通用同步/异步接收/发送器(USART)
– 支持ISO7816 T0/T1 智能卡
– 硬软件握手
– 支持RS485 及高达115 Kbps的IrDA 总线
– USART1为全调制解调控制线
· 主机/从机串行外设接口(SPI)
– 8~ 16 位可编程数据长度,可连接4个外设
· 两个 3 通道16 位定时/计数器(TC)
– 3个外部时钟输入,每条通道有2 个多功能I/O引脚
– 双PWM 产生器,捕获/波形模式,上加/下减计数能力
· 两线接口(TWI)
– 主机模式支持,所有两线Atmel EEPROM 支持
· 所有数字引脚的IEEE 1149.1 JTAG边界扫描
· 电源供应
– VDDCORE,VDDOSC及VDDPLL电压为:1.65V ~1.95V
– VDDIOP (外设I/O) 及VDDIOM (存储器I/O)电压为:1.65V~ 3.6V
体系特点
结构特点
以ARM9E-S为例介绍ARM9处理器的主要结构及其特点。ARM9E-S的结构如图4所示。其主要特点如下:
⑴32bit定点RISC处理器,改进型ARM/Thumb代码交织,增强性乘法器设计。支持实时(real-time)调试;
⑵片内指令和数据SRAM,而且指令和数据的
存储器容量可调;
⑶片内指令和数据高速缓冲器(cache)容量从4K字节到1M字节;
⑷设置保护单元(protection unit),非常适合
嵌入式应用中对
存储器进行分段和保护;
⑸采用AMBA AHB总线接口,为
外设提供统一的地址和
数据总线;
⑺支持标准基本
逻辑单元扫描测试方法学,而且支持BIST(built-in-self-test);
ARM920T运行模式
ARM920T支持7种运行模式,分别为:
(1)用户模式(usr),
ARM处理器正常的程序执行状态;
(2)快速中断模式 (fiq),
用于高速数据传输或通道处理;
(3)外部中断模式(irq),
用于通用的中断处理;
(4)管理模式(svc),
操作系统使用的保护模式;
(5)数据访问终止模式(abt),
当数据或指令预取终止时进入该模式,可用于虚拟存储及存储保护;
(6)系统模式(sys),
运行具有特权的操作系统任务;
(7)未定义指令中止模式(und)
当未定义的指令执行时进入该模式,可用于支持硬件协处理器的软件仿真。
ARM微处理器的运行模式可以通过软件改变,也可以通过外部中断或异常处理改变。大多数的应用程序运行在用户模式下,当处理器运行在用户模式下时,某些被保护的系统资源是不能被访问的。除用户模式以外,其余的6种模式称为特权模式;其中除去用户模式和系统模式以外的5种又称为异常模式,常用于处理中断或异常,以及访问受保护的系统资源等情况。
ARM920T的工作状态
从编程的角度看,ARM920T微处理器的工作状态一般有两种:
(1)ARM状态,此时处理器执行32位的、字对齐的ARM指令;
(2)Thumb状态,此时处理器执行16位的、半字对齐的Thumb指令。
ARM指令集和Thumb指令集均有切换处理器状态的指令,在程序的执行过程中,微处理器可以随时在两种工作状态之间切换,并且,处理器的工作状态的转变并不影响处理器的工作模式和相应寄存器中的内容。但ARM微处理器在开始执行代码时,应该处于ARM
状态。
当操作数寄存器的状态位(位0)为1时,可以采用执行BX指令的方法,使微处理器从
ARM状态切换到Thumb状态。此外,当处理器处于Thumb状态时发生异常(如IRQ、FIQ、Undef、Abort、SWI等),当异常处理返回时,自动切换回Thumb状态。当操作数寄存器的状态位为0时,执行BX指令可以使微处理器从Thumb状态切换到ARM状态。此外,在处理器进行异常处理时,将PC指针放入异常模式链接寄存器中,并从异常向量地址开始执行程序,也可以使处理器切换到ARM状态。
ARM920T体系结构的存储器格式
ARM920T体系结构将存储器看做是从零地址开始的字节的线性组合。从0字节到3字节放置第1个存储的字数据,从第4个字节到第7个字节放置第2个存储的字数据,依次排列。作为32位的微处理器,ARM92OT体系结构所支持的最大寻址空间为4GB。
ARM92OT体系结构可以用两种方法存储字数据,分别称为大端格式和小端格式。大端格式中字数据的高字节存储在低地址中,而字数据的低字节则存放在高地址中
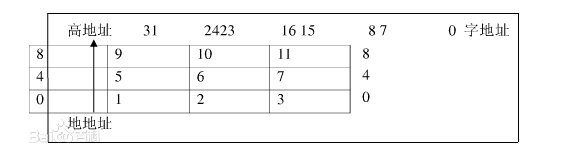
以大端格式存储数据
以小端格式存储数据
指令
⒈loads 指令与n stores指令
指令周期数的改进最明显的是loads指令和stores指令。从ARM7到ARM9这两条指令的执行时间减少了30%。
指令周期的减少是由于ARM7和ARM9两种处理器内的两个基本的微处理结构不同所造成的。
⑴ARM9有独立的指令和数据
存储器接口,允许处理器同时进行取指和读写数据。这叫作改进型
哈佛结构。而ARM7只有数据
存储器接口,它同时用来取指令和数据访问。
⑵5级流水线引入了独立的
存储器和写回流水线,分别用来访问存储器和将结果写回
寄存器。
以上两点实现了一个周期完成loads指令和stores指令。
⒉互锁(interlocks)技术
当指令需要的数据因为以前的指令没有执行完而没有准备好就会产生管道互锁。当管道互锁发生时,硬件会停止这个指令的执行,直到数据准备好为止。虽然这种技术会增加代码执行时间,但是为初期的设计者提供了巨大的方便。编译器以及汇编程序员可以通过重新设计代码的顺序或者其他方法来减少管道互锁的数量。
⒊分枝指令
ARM9和ARM7的分枝
指令周期是相同的。而且ARM9TDMI和ARM9E-S并没有对分枝指令进行预测处理。
处理能力
新一代的ARM9处理器,通过全新的设计,采用了更多的晶体管,能够达到两倍以上于ARM7处理器的处理能力。这种处理能力的提高是通过增加
时钟频率和减少指令执行周期实现的。
ARM7处理器采用3级流水线,而ARM9采用5级流水线。增加的流水线设计提高了
时钟频率和
并行处理能力。5级流水线能够将每一个指令处理分配到5个
时钟周期内,在每一个时钟周期内同时有5个指令在执行。在同样的加工工艺下,ARM9TDMI处理器的时钟频率是ARM7TDMI的1.8~2.2倍。
指令周期的改进对于处理器性能的提高有很大的帮助。性能提高的幅度依赖于代码执行时指令的重叠,这实际上是程序本身的问题。对于采用最高级的语言,一般来说,性能的提高在30%左右。
-
Cortex-A 系列处理器
Cortex-A 系列处理器是一系列处理器,支持ARM32或64位指令集,向后完全
兼容早期的ARM处理器,包括从1995年发布的ARM7TDMI处理器到2002年发布的ARMll处理器系列。
简介
32位RISCCPU开发领域中不断取得
突破,其设计的微处理器结构已经从v3发展到现在的v7。Cortex系列处理器是基于ARMv7架构的,分为Cortex-M、Cortex-R和Cortex-A三类。由于应用领域的不同,基于v7架构的Cortex处理器系列所采用的技术也不相同。基于v7A的称为“Cortex-A系列。高性能的
Cortex-A15、可伸缩的
Cortex-A9、经过市场验证的
Cortex-A8处理器以及高效的
Cortex-A7和
Cortex-A5处理器均共享同一体系结构,因此具有完整的应用兼容性,支持传统的ARM、
Thumb指令集和新增的高性能紧凑型Thumb-2指令集。
Cortex-A15和Cortex-A7都支持ARMv7A体系结构的扩展,从而为大型物理地址访问和硬件虚拟化以及启用big.LITTLE处理的AMBA4ACE一致性提供支持。
ARMv7包括3个关键要素:NEON单指令多数据(SIMD)单元、ARMtrustZone安全扩展、以及thumb2指令集,通过16位和32位混合长度指令以减小代码长度。
高性能
Cortex-A 设备可为其目标应用领域提供各种可伸缩的能效性能点。一些说明示例如下:
Cortex-A15 ,可为新一代移动基础结构应用和要求苛刻的无线基础结构应用提供性能最高的解决方案
Cortex-A7,可采用独立、多核配置实现,提供 800 MHz - 1.2 GHz 的典型频率,也可以与 Cortex-A15 结合用于 big.LITTLE 处理
Cortex-A9 实现,可提供 800 MHz - 2 GHz 的标准频率,每个内核可提供 5000 DMIPS 的性能
Cortex-A8 单核解决方案,可提供经济有效的高性能,在 600 MHz - 1 GHz 的频率下,提供的性能超过 2000 DMIPS
Cortex-A5 低成本实现,在 400- 800 MHz 的频率下,提供的性能超过 1200 DMIPS。
多核技术
Cortex-A5、[1] Cortex-A7、Cortex-A9 和 Cortex-A15 处理器都支持 ARM 的第二代多核技术
单核到四核实现,支持面向性能的应用领域 支持对称和非对称的操作系统实现 通过加速器一致性端口 (ACP) 在导出到系统的整个处理器中保持一致性 Cortex-A7 和 Cortex-A15 将多核一致性扩展至 AMBA4 ACE 的 1~4 核群集以上(AMBA 一致性扩展)
高级扩展
除了具有与上一代经典 ARM 和 Thumb® 体系结构的二进制兼容性外,Cortex-A 类处理器还通过以下技术扩展提供了更多优势
Thumb-2,提供最佳代码大小和性能
TrustZone 安全扩展,提供可信计算
Jazelle 技术,提高执行环境(如 Java、.Net、MSIL、Python 和 Perl)速度。
产品应用
ARM公司的Cortex-A系列处理器适用于具有高计算要求、运行丰富操作系统以及提供交互媒体和图形体验的应用领域。从最新技术的移动Internet必备设备(如手机和超便携的上网本或智能本)到汽车信息娱乐系统和下一代数字电视系统。也可以用于其他移动便携式设备,还可以用于数字电视、机顶盒、企业网络、打印机和服务器解决方案。这一系列的处理器具有高效低耗等特点,比较适合配置于各种移动平台。
虽然Cortex-A处理器正朝着提供完全的Internet体验的方向发展,但其应用也很广泛,包括:
|
产品类型
|
应用
|
|---|
|
|
上网本、智能本、输入板、电子书阅读器、瘦客户端
|
|
手机
|
智能手机、特色手机
|
|
数字家电
|
|
|
汽车
|
信息娱乐、导航
|
|
企业
|
激光打印机、 路由器、无线基站、VOIP 电话和设备 |
|
无线基础结构
|
Web 2.0、无线基站、交换机、服务器
|
ARM Cortex™-A5 处理器是能效最高、成本最低的处理器,能够向最广泛的设备提供 Internet 访问:从入门级智能手机、低成本手机和智能移动终端到普遍采用的嵌入式、消费类和工业设备。
Cortex-A5 处理器可为现有 ARM926EJ-S™ 和 ARM1176JZ-S™ 处理器设计提供很有价值的迁移途径。它可以获得比 ARM1176JZ-S 更好的性能,比 ARM926EJ-S 更好的功效和能效以及 100% 的 Cortex-A 兼容性。
这些处理器向特别注重功耗和成本的应用程序提供高端功能,其中包括:
多重处理功能,可以获得可伸缩、高能效性能
高性能内存系统,包括高速缓存和内存管理单元
Cortex-A7 处理器
ARM Cortex™-A7 MPCore™ 处理器是 ARM 迄今为止开发的最有效的应用处理器,它显著扩展了 ARM 在未来入门级智能手机、平板电脑以及其他高级移动设备方面的低功耗领先地位。
Cortex-A7 处理器的体系结构和功能集与 Cortex-A15 处理器完全相同,不同这处在于,Cortex-A7 处理器的微体系结构侧重于提供最佳能效,因此这两种处理器可在
big.LITTLE配置中协同工作,软件可以在高能效 Cortex-A7 处理器上运行 也可以在需要时在高性能 Cortex-A15 处理器上运行 无需重新编译,[2]
从而提供高性能与超低功耗的终极组合。
作为独立处理器,单个 Cortex-A7 处理器的能源效率是 ARM Cortex-A8 处理器(支持如今的许多最流行智能手机)的 5 倍,性能提升 50%,而尺寸仅为后者的五分之一。
Cortex-A7 可以使 2013-2014 年期间低于 100 美元价格点的入门级智能手机与 2010 年 500 美元的高端智能手机相媲美。这些入门级智能手机在发展中世界将重新定义连接和 Internet 使用。
该处理器与其他 Cortex-A 系列处理器完全兼容并整合了高性能 Cortex-A15 处理器的所有功能,包括虚拟化、大物理地址扩展 (LPAE) NEON 高级 SIMD 和 AMBA 4 ACE 一致性。
最佳的功效和占用空间,可作为独立的应用处理器 性能高于 2011 年主流智能手机 CPU 性能提升高达 20% 而功耗降低 60%AMBA 4 ACE 一致性接口支持大小 CPU 群集之间 20us 以下的上下文迁移
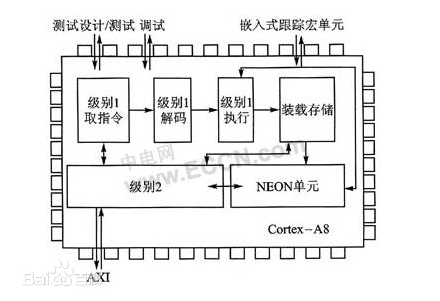
ARMCortex-A8处理器是一款适用于复杂操作系统及用户应用的应用处理器,其结构如图所示。支持智能能源管理(IEM,IntelligentEnergyManger)技术的ARMArtisan库以及先进的泄漏控制技术,使得Cortex-A8处理器实现了非凡的速度和功耗效率在65nm上艺下,ARMcortex-A8处理器的功耗不到300mW,能够提供高性能和低功耗它第一次为低费用、高容量的产品带来了台式机级别的性能
A8处理器结构
Cortex-A8处理器是第一款基于下一代ARMv7架构的应用处理器,使用了能够带来更高性能、更低功耗和更高代码密度的Thumb-2技术它首次采用了强大的NEON信号处理扩展集,为H.264和MP3等媒体编解码提供加速
Cortex-A8的解决方案还包括Jazelle-RCTJava加速技术,对实时(JIT)和动态调整编译(DAC)提供最优化,同时减少内存占用空间高达3倍该处理器配置了先进的超标量体系结构流水线,能够同时执行多条指令,并且提供超过2.0DMIPS/MHz的性能处理器集成了一个可调尺寸的二级高速缓冲存储器,能够同高速的16KB或者32KB一级高速缓冲存储器一起工作,从而达到最快的读取速度和最大的吞吐量新处理器还配置了用于安全交易和数字版权管理的TrustZone技术,以及实现低功耗管理的IEM功能
Cortex-A8处理器使用了先进的分支预测技术,并且具有专用的NEON整型和浮点型流水线进行媒体和信号处理在使用小于4mm2的硅片及低功耗的65nm工艺的情况下,Cortex-A8处理器的运行频率将高于600MHz(不包括NEON追踪技术和二级高速缓冲存储器)在高性能的90nm和65nm工艺下,Cortex-A8处理器运行频率最高可达1GHz,能够满足高性能消费产品设计的需要。
Cortex-A9处理器
ARM Cortex™-A9 处理器提供了史无前例的高性能和高能效,从而使其成为需要在低功耗或散热受限的成本敏感型设备中提供高性能的设计的理想解决方案。 它既可用作单核处理器,也可用作可配置的多核处理器,同时可提供可合成或硬宏实现。该处理器适用于各种应用领域,从而能够对多个市场进行稳定的软件投资。
与高性能计算平台消耗的功率相比,ARM Cortex-A9 处理器可提供功率更低的卓越功能,其中包括:
无与伦比的性能,2GHz 标准操作可提供 TSMC 40G 硬宏实现
以低功耗为目标的单核实现,面向成本敏感型设备
利用高级 MPCore 技术,最多可扩展为 4 个一致的内核
Cortex-A15 处理器
ARM Cortex™-A15 MPCore™ 处理器是性能高且可授予许可的处理器。它提供前所未有的处理功能,与低功耗特性相结合,在各种市场上成就了卓越的产品,包括智能手机、平板电脑、移动计算、高端数字家电、服务器和无线基础结构。Cortex-A15 MPCore 处理器提供了性能、功能和能效的独特组合,进一步加强了 ARM 在这些高价值和高容量应用细分市场中的领导地位。
Cortex-A15 MPCore 处理器是 Cortex-A 系列处理器的最新成员,确保在应用方面与所有其他获得高度赞誉的 Cortex-A 处理器完全兼容。这样,就可以立即访问已得到认可的开发平台和软件体系,包括 Android™、Adobe® Flash® Player、Java Platform Standard Edition (Java SE)、JavaFX、Linux、Microsoft Windows Embedded、Symbian 和 Ubuntu 以及 700 多个 ARM Connected Community™ 成员,这些成员提供应用软件、硬件和软件开发工具、中间件以及 SoC 设计服务。
Cortex-A15 MPCore 处理器具有无序超标量管道,带有紧密耦合的低延迟 2 级高速缓存,该高速缓存的大小最高可达 4MB。
浮点和 NEON™ 媒体性能方面的其他改进使设备能够为消费者提供下一代用户体验,并为 Web 基础结构应用提供高性能计算。
预计 Cortex-A15 MPCore 处理器的移动配置所能提供的性能是当前的高级智能手机性能的五倍还多。在高级基础结构应用中,Cortex-A15 的运行速度最高可达 2.5GHz,这将支持在不断降低功耗、散热和成本预算方面实现高度可伸缩的解决方案。
Cortex-A57
cortex-a57是ARM针对2013年、2014年和2015年设计起点的CPU产品系列的旗舰级CPU,它采用armv8-a架构,提供64位功能,而且通过Aarch32执行状态,保持与ARMv7架构的完全后向兼容性。在高于4GB的内存广泛使用之前,64位并不是移动系统真正必需的,即便到那时也可以使用扩展物理寻址技术来解决,但尽早推出64位,可以实现更长、更顺畅的软件迁移,让高性能应用程序能够充分利用更大虚拟地址范围来运行内容创建应用程序,例如视频编辑、照片编辑和增强现实。新架构可以运行64位操作系统,并在操作系统上无缝混合运行32位和64位应用程序。ARMv8架构可以实现状态之间的轻松转换。
除了ARMv8的架构优势之外,Cortex-A57还提高了单个时钟周期性能,比高性能的Cortex-A15CPU高出了20%至40%。它还改进了二级高速缓存的的设计以及内存系统的其他组件,极大的提高了能效。Cortex-A57将为移动系统提供前所未有的高能效性能水平,而借助big.LITTLE,SoC能以很低的平均功耗做到这一点。
Cortex-A72是ARM性能最出色、最先进的处理器。于2015年年初正式发布的Cortex-A72是基于ARMv8-A架构、并构建于Cortex-A57处理器在移动和企业设备领域成功的基础之上。在相同的移动设备电池寿命限制下,Cortex-A72能相较基于Cortex-A15的设备提供3.5倍的性能表现,展现优异的整体功耗效率。
Cortex-A72的强化性能和功耗水平重新定义了2016年高端设备为消费者带来的丰富连接和情境感知(context-aware)的体验,这些高端设备涵盖高阶的智能手机、中型平板电脑、大型平板电脑、翻盖式笔记本、一直到外形规格可变化的移动设备。未来的企业基站和服务器芯片也能受惠于Cortex-A72的性能,并在其优异的能效基础上,在有限的功耗范围内增加内核数量,提升工作负载量。
Cortex-A72可在芯片上单独实现,也可以搭配Cortex-A53处理器与ARMCoreLinkTMCCI高速缓存一致性互连(CacheCoherentInterconnect)构成ARMbig.LITTLETM配置,进一步提升能效。
Cortex-A72是目前基于ARMv8-A架构处理器中性能最高的处理器。它再次展现了ARM在处理器技术的领先地位,在提升新的性能标准之余,同时大幅降低功耗,可广泛地扩展应用于移动与企业设备。
智能手机是目前大众主要的计算平台,提供使用者随时随地创造、强化以及使用内容的功能。拟真且复杂的图像与视频捕捉、主机级游戏般的性能、用来进行文档与办公应用流畅处理的生产力套件等,这些需求促使Cortex-A72如此高端性能的处理器面市,执行这些服务的设备被要求在更轻薄、更时尚的外形设计之下,必须全天候处理日益增长的CPU和GPU工作负载,这使得制造商不得不将精力用在寻找高能效的处理器内核。在智能手机、平板电脑、甚至是大尺寸的移动设备,Cortex-A72能通过出色的能效与内存系统,提功绝佳的用户体验。将Cortex-A72与Cortex-A53处理器以ARMbig.LITTLE™(大小核)处理器进行配置,可以扩展整体的性能与效率表现。